Genre Recognition#
import IPython.display as ipd
import matplotlib.pyplot as plt
import librosa.display
import numpy
import pandas
import sklearn
from mirdotcom import mirdotcom
mirdotcom.init()
Load Audio#
Load 30 seconds of an audio file:
filename_brahms = mirdotcom.get_audio("brahms_hungarian_dance_5.mp3")
x_brahms, sr_brahms = librosa.load(filename_brahms, duration=30)
Load 30 seconds of another audio file:
filename_busta = mirdotcom.get_audio("busta_rhymes_hits_for_days.mp3")
x_busta, sr_busta = librosa.load(filename_busta, duration=30)
Play the audio files:
ipd.Audio(x_brahms, rate=sr_brahms)
ipd.Audio(x_busta, rate=sr_busta)
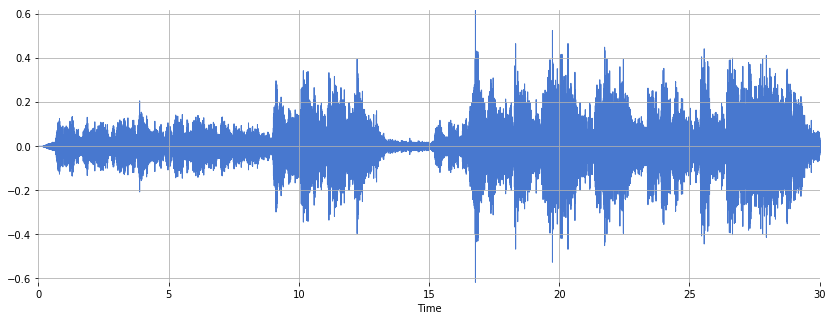
Plot the time-domain waveform of the audio signals:
plt.figure(figsize=(14, 5))
librosa.display.waveshow(x_brahms, sr=sr_brahms)
plt.ylabel("Autocorrelation")
<matplotlib.collections.PolyCollection at 0x1128cce80>
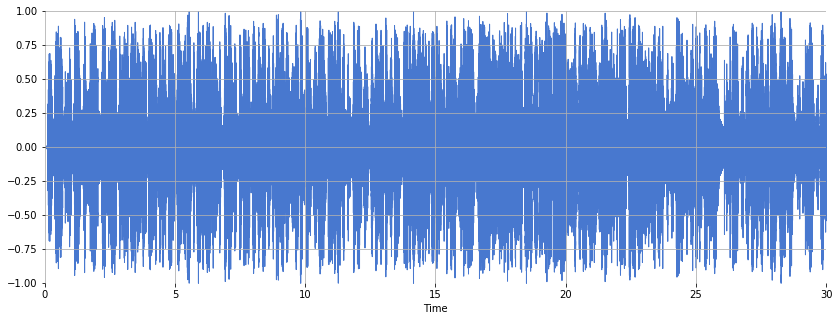
plt.figure(figsize=(14, 5))
librosa.display.waveshow(x_busta, sr=sr_busta)
plt.ylabel("Autocorrelation")
<matplotlib.collections.PolyCollection at 0x112b20b38>
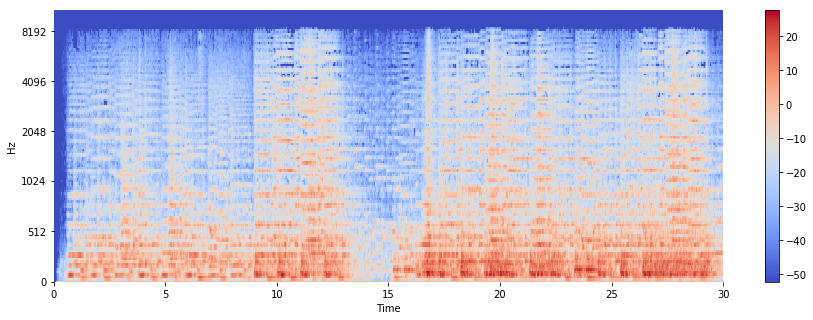
Compute the power melspectrogram:
S_brahms = librosa.feature.melspectrogram(y=x_brahms, sr=sr_brahms, power=2.0)
Convert amplitude to decibels:
Sdb_brahms = librosa.power_to_db(S_brahms)
plt.figure(figsize=(15, 5))
librosa.display.specshow(Sdb_brahms, sr=sr_brahms, x_axis="time", y_axis="mel")
plt.colorbar()
<matplotlib.colorbar.Colorbar at 0x111636240>
S_busta = librosa.feature.melspectrogram(y=x_busta, sr=sr_busta, power=2.0)
Sdb_busta = librosa.power_to_db(S_busta)
plt.figure(figsize=(15, 5))
librosa.display.specshow(Sdb_busta, sr=sr_busta, x_axis="time", y_axis="mel")
plt.colorbar()
<matplotlib.colorbar.Colorbar at 0x1116a8dd8>
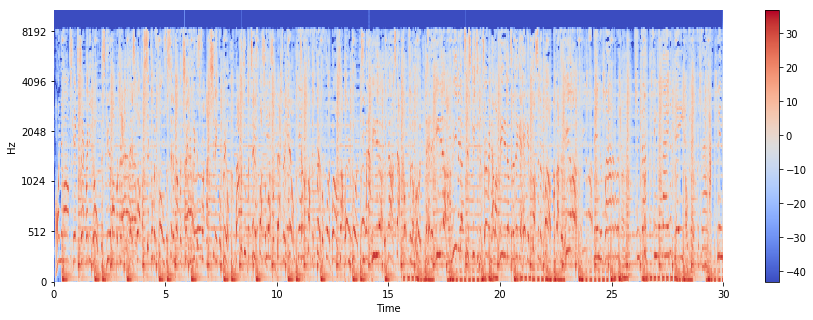
In what ways do the time-domain waveform and spectrogram differ between the two files? What differences in musical attributes might this reflect? What additional insights are gained from plotting the spectrogram?
Extract Features#
For each segment, compute the MFCCs. Experiment with n_mfcc to select a different number of coefficients, e.g. 12.
n_mfcc = 12
mfcc_brahms = librosa.feature.mfcc(y=x_brahms, sr=sr_brahms, n_mfcc=n_mfcc).T
We transpose the result to accommodate scikit-learn which assumes that each row is one observation, and each column is one feature dimension:
mfcc_brahms.shape
(1292, 12)
mfcc_brahms.mean(axis=0)
array([-220.93906043, 135.8146764 , -16.1986192 , 60.09800836,
-10.74171479, 24.57344387, -10.06327054, 9.731529 ,
-8.28940164, 5.63699785, -3.99416235, -2.94650237])
mfcc_brahms.std(axis=0)
array([77.8507174 , 18.85226412, 14.43771304, 11.0615969 , 11.15194374,
9.53373496, 8.30995864, 8.35195864, 8.34518744, 7.3264163 ,
6.02968518, 5.75487171])
Scale the features to have zero mean and unit variance:
scaler = sklearn.preprocessing.StandardScaler()
mfcc_brahms_scaled = scaler.fit_transform(mfcc_brahms)
# is equivalent to:
# scaler.fit(mfcc_brahms)
# mfcc_brahms_scaled = scaler.transform(mfcc_brahms)
Verify that the scaling worked:
mfcc_brahms_scaled.mean(axis=0)
array([ 2.39780676e-15, -1.24975709e-14, 1.43783334e-16, -1.83547707e-15,
-7.79390312e-16, -1.24393100e-15, -7.93998510e-16, -1.64694539e-15,
6.99152638e-16, 5.68860404e-17, 9.52110767e-17, 1.04525951e-15])
mfcc_brahms_scaled.std(axis=0)
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
Extract MFCCs from the second audio file.
mfcc_busta = librosa.feature.mfcc(y=x_busta, sr=sr_busta, n_mfcc=n_mfcc).T
We transpose the resulting matrix so that each row is one observation, i.e. one set of MFCCs. Note that the shape and size of the resulting MFCC matrix is equivalent to that for the first audio file:
print(mfcc_brahms.shape)
print(mfcc_busta.shape)
(1292, 12)
(1292, 12)
Scale the resulting MFCC features to have approximately zero mean and unit variance. Re-use the scaler from above.
mfcc_busta_scaled = scaler.transform(mfcc_busta)
Verify that the mean of the MFCCs for the second audio file is approximately equal to zero and the variance is approximately equal to one.
mfcc_busta_scaled.mean(axis=0)
array([ 2.27178743, -0.98521415, -1.01236983, -0.62225477, -2.07693829,
0.70574552, -0.99776438, 1.37918189, -1.1971934 , 0.98541195,
-1.05935641, 1.65934091])
mfcc_busta_scaled.std(axis=0)
array([0.63033628, 1.26643623, 1.30243229, 1.47714284, 1.49474468,
1.66052301, 1.65450649, 1.50051709, 1.2635102 , 1.31561208,
1.64746289, 1.63874381])
Train a Classifier#
Concatenate all of the scaled feature vectors into one feature table.
features = numpy.vstack((mfcc_brahms_scaled, mfcc_busta_scaled))
features.shape
(2584, 12)
Construct a vector of target/reference labels, where 0 refers to the first audio file, and 1 refers to the second audio file.
labels = numpy.concatenate(
(numpy.zeros(len(mfcc_brahms_scaled)), numpy.ones(len(mfcc_busta_scaled)))
)
labels.shape
(2584,)
Create a classifer model object:
# Support Vector Machine
model = sklearn.svm.SVC()
Train the classifier:
model.fit(features, labels)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
Run the Classifier#
To test the classifier, we will extract an unused 10-second segment from the earlier audio fields as test excerpts:
x_brahms_test, sr_brahms = librosa.load(filename_brahms, duration=10, offset=120)
x_busta_test, sr_busta = librosa.load(filename_busta, duration=10, offset=120)
Listen to both of the test audio excerpts:
ipd.display(ipd.Audio(x_brahms_test, rate=sr_brahms))
ipd.display(ipd.Audio(x_busta_test, rate=sr_brahms))
ipd.Audio(x_busta_test, rate=sr_busta)
Compute MFCCs from both of the test audio excerpts:
mfcc_brahms_test = librosa.feature.mfcc(y=x_brahms_test, sr=sr_brahms, n_mfcc=n_mfcc).T
mfcc_busta_test = librosa.feature.mfcc(y=x_busta_test, sr=sr_busta, n_mfcc=n_mfcc).T
print(mfcc_brahms_test.shape)
print(mfcc_busta_test.shape)
(431, 12)
(431, 12)
Scale the MFCCs using the previous scaler:
mfcc_brahms_test_scaled = scaler.transform(mfcc_brahms_test)
mfcc_busta_test_scaled = scaler.transform(mfcc_busta_test)
Concatenate all test features together:
features_test = numpy.vstack((mfcc_brahms_test_scaled, mfcc_busta_test_scaled))
Concatenate all test labels together:
labels_test = numpy.concatenate(
(numpy.zeros(len(mfcc_brahms_test)), numpy.ones(len(mfcc_busta_test)))
)
Compute the predicted labels:
predicted_labels = model.predict(features_test)
Finally, compute the accuracy score of the classifier on the test data:
score = model.score(features_test, labels_test)
score
0.9756380510440835
Currently, the classifier returns one prediction for every MFCC vector in the test audio signal. Let’s modify the procedure above such that the classifier returns a single prediction for a 10-second excerpt.
predicted_labels = model.predict(mfcc_brahms_test_scaled)
predicted_labels.shape
(431,)
predicted_labels
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 0.,
0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 0., 1., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1.,
1., 1., 1., 0., 0., 1.])
unique_labels, unique_counts = numpy.unique(predicted_labels, return_counts=True)
unique_labels, unique_counts
(array([0., 1.]), array([412, 19]))
It worked! Notice how Class 0 has a majority of the predictions:
unique_labels[numpy.argmax(unique_counts)]
0.0
Busta Rhymes;
predicted_labels = model.predict(mfcc_busta_test_scaled)
unique_labels, unique_counts = numpy.unique(predicted_labels, return_counts=True)
unique_labels, unique_counts
(array([0., 1.]), array([ 2, 429]))
It worked! Notice how Class 1 now has a majority of the predictions:
unique_labels[numpy.argmax(unique_counts)]
1.0
Analysis in Pandas#
Read the MFCC features from the first test audio excerpt into a data frame:
df_brahms = pandas.DataFrame(mfcc_brahms_test_scaled)
df_brahms.shape
(431, 12)
df_brahms.head()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.104773 | -0.219520 | 0.373516 | 0.225778 | 0.762844 | -1.075204 | 1.238187 | 0.494730 | 1.696641 | -0.246510 | 1.042416 | 0.787659 |
| 1 | -0.108518 | -0.099241 | 0.213567 | 0.087639 | 0.337936 | -1.322424 | 1.389348 | 0.127674 | 1.700745 | -0.842573 | 0.540719 | -0.009888 |
| 2 | -0.145666 | -0.031331 | -0.183363 | 0.029870 | 0.169971 | -1.172648 | 1.719064 | -0.022895 | 2.273048 | -1.907215 | 0.802041 | 0.053442 |
| 3 | -0.143149 | -0.201561 | -0.037646 | -0.111831 | 0.268106 | -1.172131 | 1.068313 | -0.703127 | 1.579066 | -1.128547 | 0.714915 | 0.736582 |
| 4 | -0.221894 | -0.123148 | 0.367584 | 0.053476 | 0.625240 | -1.331675 | 0.701075 | -1.419556 | 1.173309 | -0.614770 | -0.158624 | 0.718170 |
df_busta = pandas.DataFrame(mfcc_busta_test_scaled)
Compute the pairwise correlation of every pair of 12 MFCCs against one another for both test audio excerpts. For each audio excerpt, which pair of MFCCs are the most correlated? least correlated?
df_brahms.corr()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.000000 | -0.229494 | -0.764146 | 0.731726 | -0.816695 | 0.895659 | -0.714249 | 0.799892 | -0.497270 | 0.793114 | -0.238424 | 0.034713 |
| 1 | -0.229494 | 1.000000 | 0.444239 | -0.164949 | 0.557669 | -0.282145 | 0.500007 | -0.334071 | 0.374219 | -0.152090 | 0.324334 | -0.452799 |
| 2 | -0.764146 | 0.444239 | 1.000000 | -0.488526 | 0.757116 | -0.594214 | 0.571241 | -0.582506 | 0.371949 | -0.533613 | 0.131372 | -0.134386 |
| 3 | 0.731726 | -0.164949 | -0.488526 | 1.000000 | -0.523240 | 0.649464 | -0.416755 | 0.546723 | -0.052526 | 0.629756 | -0.100783 | -0.046484 |
| 4 | -0.816695 | 0.557669 | 0.757116 | -0.523240 | 1.000000 | -0.686828 | 0.753812 | -0.656629 | 0.500207 | -0.549111 | 0.288271 | -0.245888 |
| 5 | 0.895659 | -0.282145 | -0.594214 | 0.649464 | -0.686828 | 1.000000 | -0.601323 | 0.771339 | -0.527417 | 0.701983 | -0.306818 | 0.044711 |
| 6 | -0.714249 | 0.500007 | 0.571241 | -0.416755 | 0.753812 | -0.601323 | 1.000000 | -0.482706 | 0.529517 | -0.552516 | 0.253997 | -0.183942 |
| 7 | 0.799892 | -0.334071 | -0.582506 | 0.546723 | -0.656629 | 0.771339 | -0.482706 | 1.000000 | -0.345140 | 0.695456 | -0.272389 | 0.021364 |
| 8 | -0.497270 | 0.374219 | 0.371949 | -0.052526 | 0.500207 | -0.527417 | 0.529517 | -0.345140 | 1.000000 | -0.272413 | 0.273572 | -0.278589 |
| 9 | 0.793114 | -0.152090 | -0.533613 | 0.629756 | -0.549111 | 0.701983 | -0.552516 | 0.695456 | -0.272413 | 1.000000 | -0.061747 | -0.140820 |
| 10 | -0.238424 | 0.324334 | 0.131372 | -0.100783 | 0.288271 | -0.306818 | 0.253997 | -0.272389 | 0.273572 | -0.061747 | 1.000000 | -0.027108 |
| 11 | 0.034713 | -0.452799 | -0.134386 | -0.046484 | -0.245888 | 0.044711 | -0.183942 | 0.021364 | -0.278589 | -0.140820 | -0.027108 | 1.000000 |
df_busta.corr()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.000000 | 0.141643 | -0.607050 | 0.214858 | -0.516394 | 0.300162 | -0.342024 | 0.376984 | -0.116558 | 0.119532 | -0.223083 | 0.089952 |
| 1 | 0.141643 | 1.000000 | -0.094776 | -0.205667 | 0.213192 | -0.149389 | 0.219879 | -0.071229 | 0.243601 | -0.074410 | 0.208512 | 0.010957 |
| 2 | -0.607050 | -0.094776 | 1.000000 | -0.069729 | 0.409906 | -0.007501 | 0.090853 | 0.122450 | -0.041048 | 0.278018 | 0.138320 | 0.283167 |
| 3 | 0.214858 | -0.205667 | -0.069729 | 1.000000 | 0.171071 | 0.044608 | 0.093059 | 0.160301 | 0.294998 | -0.071344 | -0.124506 | 0.189648 |
| 4 | -0.516394 | 0.213192 | 0.409906 | 0.171071 | 1.000000 | -0.183478 | 0.249568 | -0.028854 | 0.257815 | 0.097381 | 0.108769 | 0.307512 |
| 5 | 0.300162 | -0.149389 | -0.007501 | 0.044608 | -0.183478 | 1.000000 | 0.052644 | 0.338824 | 0.059013 | 0.330453 | 0.318902 | 0.082445 |
| 6 | -0.342024 | 0.219879 | 0.090853 | 0.093059 | 0.249568 | 0.052644 | 1.000000 | 0.039506 | 0.501191 | -0.006951 | 0.257304 | 0.019874 |
| 7 | 0.376984 | -0.071229 | 0.122450 | 0.160301 | -0.028854 | 0.338824 | 0.039506 | 1.000000 | 0.005013 | 0.421432 | 0.002684 | 0.393715 |
| 8 | -0.116558 | 0.243601 | -0.041048 | 0.294998 | 0.257815 | 0.059013 | 0.501191 | 0.005013 | 1.000000 | 0.054719 | 0.250360 | 0.153306 |
| 9 | 0.119532 | -0.074410 | 0.278018 | -0.071344 | 0.097381 | 0.330453 | -0.006951 | 0.421432 | 0.054719 | 1.000000 | 0.198342 | 0.496046 |
| 10 | -0.223083 | 0.208512 | 0.138320 | -0.124506 | 0.108769 | 0.318902 | 0.257304 | 0.002684 | 0.250360 | 0.198342 | 1.000000 | 0.180908 |
| 11 | 0.089952 | 0.010957 | 0.283167 | 0.189648 | 0.307512 | 0.082445 | 0.019874 | 0.393715 | 0.153306 | 0.496046 | 0.180908 | 1.000000 |
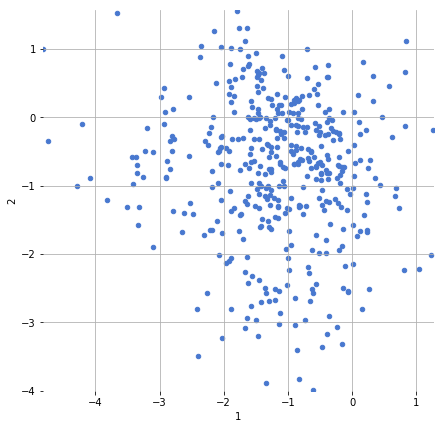
Display a scatter plot of any two of the MFCC dimensions (i.e. columns of the data frame) against one another. Try for multiple pairs of MFCC dimensions.
df_brahms.plot.scatter(1, 2, figsize=(7, 7))
<matplotlib.axes._subplots.AxesSubplot at 0x112f98cc0>
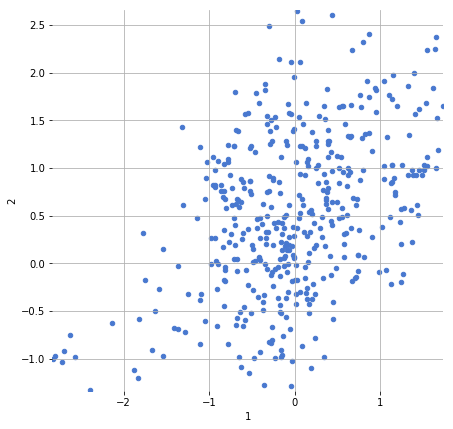
Display a scatter plot of any two of the MFCC dimensions (i.e. columns of the data frame) against one another. Try for multiple pairs of MFCC dimensions.
df_busta.plot.scatter(1, 2, figsize=(7, 7))
<matplotlib.axes._subplots.AxesSubplot at 0x11304ab00>
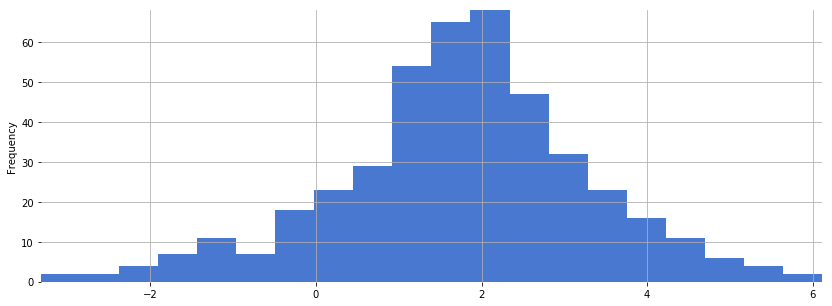
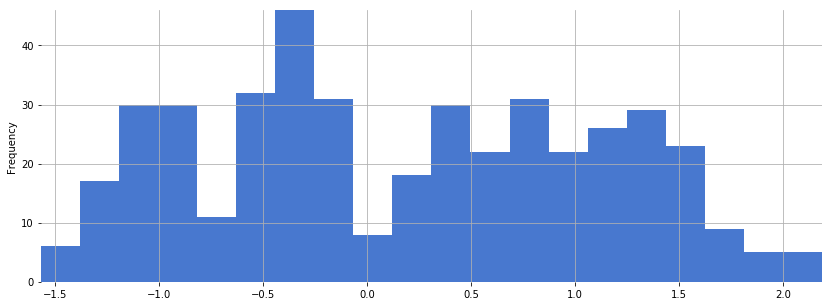
Plot a histogram of all values across a single MFCC, i.e. MFCC coefficient number. Repeat for a few different MFCC numbers:
df_brahms[0].plot.hist(bins=20, figsize=(14, 5))
<matplotlib.axes._subplots.AxesSubplot at 0x1116d74e0>
df_busta[0].plot.hist(bins=20, figsize=(14, 5))
<matplotlib.axes._subplots.AxesSubplot at 0x114cd1ba8>
df_brahms[11].plot.hist(bins=20, figsize=(14, 5))
<matplotlib.axes._subplots.AxesSubplot at 0x10556c0f0>
df_busta[11].plot.hist(bins=20, figsize=(14, 5))
<matplotlib.axes._subplots.AxesSubplot at 0x111501f60>